More news organizations are suing OpenAI for copyright infringement
Add more copyright lawsuits levied against OpenAI to the growing pile.
On Wednesday, news organizations the Intercept, Raw Story, and AlterNetfiled lawsuits against OpenAI for copyright infringement in the Southern District of New York. The Intercept also includes Microsoft in the lawsuit, whose tool Copilot uses OpenAI's model GPT-4. The lawsuits allege OpenAI (and Microsoft in the case of The Intercept) violated the Digital Millennium Copyright Act, which prohibits online service providers from removing copyright information from digital content.
SEE ALSO:What was Sora trained on? Creatives demand answers.ChatGPT's ability to provide informed, conversational responses was built on the backs of human-created content scraped from the web through datasets like Common Crawl and OpenAI's WebText and WebText 2. A December lawsuit by the New York Timesagainst OpenAI and Microsoft claimed ChatGPT plagiarized verbatim texts from its stories, without credit or compensation. Similarly, in August 2023, class-action lawsuits were filed against Google and OpenAI for using individuals' personal data to train the model.
The complaints accuse OpenAI of removing copyright information like authorship and titles, and avoiding paying licensing fees for work created by journalists. The Raw Storyand AlterNetsuit also claims OpenAI knowingly used copyrighted works because OpenAI created tools for publishers to block their works from being scraped for training data.
"When they populated their training sets with works of journalism, Defendants had a choice: they could train ChatGPT using works of journalism with the copyright management information protected by the DMCA intact, or they could strip it away," said the lawsuits. "Defendants chose the latter, and in the process, trained ChatGPT not to acknowledge or respect copyright, not to notify ChatGPT users when the responses they received were protected by journalists' copyrights, and not to provide attribution when using the works of human journalists."
This is likely not the last copyright infringement lawsuit case against OpenAI or other makers of generative AI tools. Soon after ChatGPT's release, questions emerged about the training data that was used. And the proliferation of AI models and new tools like OpenAI's video generator Sora.
Related Stories
- The New York Times sues OpenAI and Microsoft for copyright infringement
- Tumblr users, here's what to know about Tumblr selling your data to OpenAI and MidJourney
- U.S. court dismisses most claims against OpenAI in copyright class action
Other news organizations are taking a different approach by negotiating licensing deals with OpenAI. The Associated Press and German media company Axel Springer both have deals with the ChatGPT maker.
However it all shakes out, the great AI copyright battle is in full swing.
(责任编辑:新闻中心)
 “笋货”上市采购旺!清远西牛麻竹笋迎秋季尝鲜热
“笋货”上市采购旺!清远西牛麻竹笋迎秋季尝鲜热 New tandem perovskite
New tandem perovskite “我特意来广东找老婆饼!”加拿大客商跨越万里寻广府好饼
“我特意来广东找老婆饼!”加拿大客商跨越万里寻广府好饼 Mike Pence's religion: Why the Trump VP pick is quiet about his beliefs.
Mike Pence's religion: Why the Trump VP pick is quiet about his beliefs.- “笋货”上市采购旺!清远西牛麻竹笋迎秋季尝鲜热
- How to unblock Xnxx for free
- Finally Nintendo acknowledges that Mario is no longer a plumber
- The Never Trump voice vote at the GOP convention was really close.
- Elon Musk is wrong about AI
- 雅安公安接连破获两起汉源湖非法捕捞案
- 从化岭丰糯荔枝,全国银奖!
- 华创公司:坚持绿色发展,创建新会区陈皮庄园
- Put Thanos' face on a pumpkin and you'll get a pretty glorious Photoshop battle
-
 Ocean Energy has deployed its 826-tonne wave energy converter buoy OE-35 at the US Navy's Wave Energ
...[详细]
Ocean Energy has deployed its 826-tonne wave energy converter buoy OE-35 at the US Navy's Wave Energ
...[详细]
-
 福兴敬老院投入使用援建汇聚爱心温暖老人“房间舒适明亮,餐厅准备了可口的菜肴,活动室可以看书、下棋、跳舞……”谈起自己的新家——雨城区福兴敬老院,杨国兆等33位老人赞不绝口。雨城区福兴敬老院是上海市慈善
...[详细]
福兴敬老院投入使用援建汇聚爱心温暖老人“房间舒适明亮,餐厅准备了可口的菜肴,活动室可以看书、下棋、跳舞……”谈起自己的新家——雨城区福兴敬老院,杨国兆等33位老人赞不绝口。雨城区福兴敬老院是上海市慈善
...[详细]
-
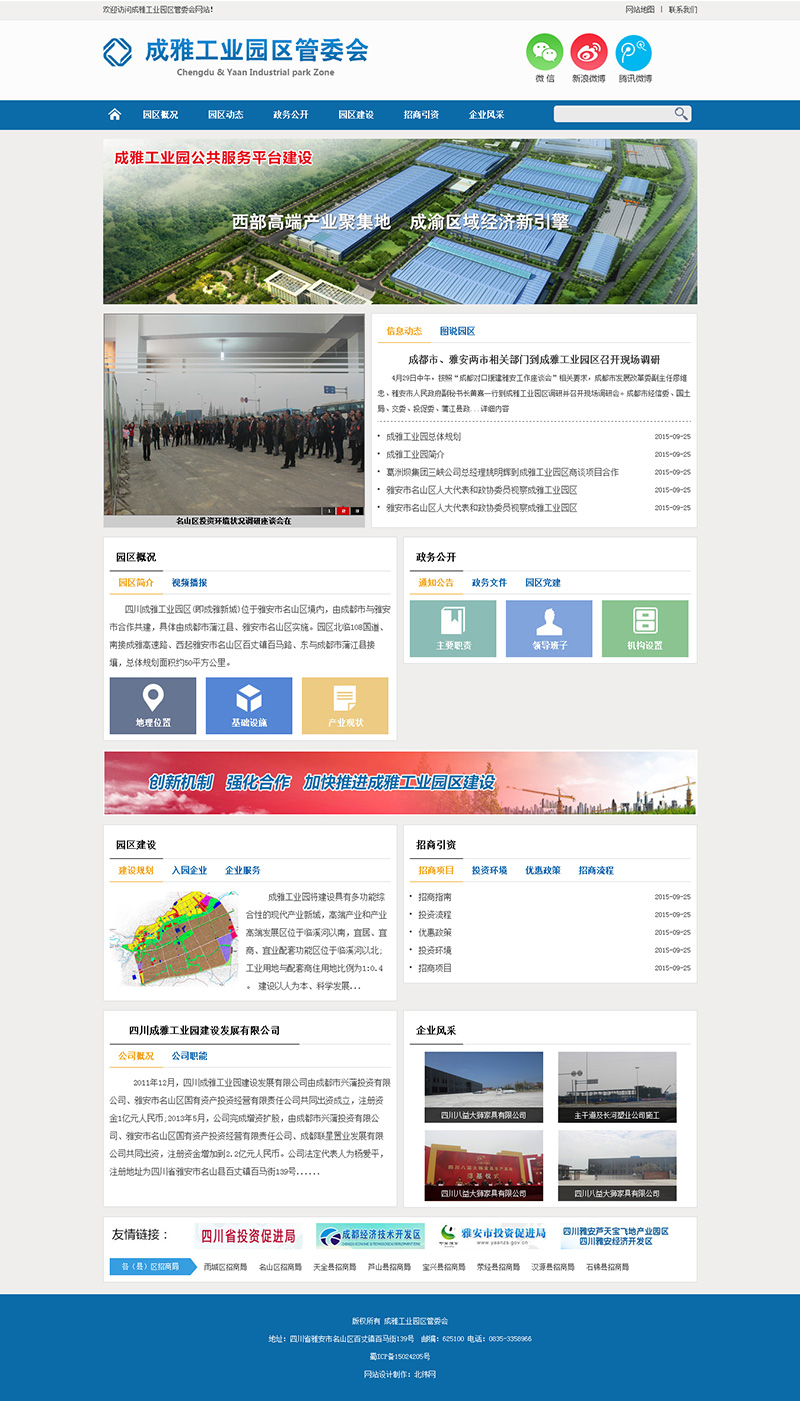 北纬网讯 近日,四川成雅工业园区管委会官方网站(http://www.cygyyq.com/)正式开通上线。网站开设了园区概况、园区动态、政务公开、园区建设、招商引资、企业风采等多个栏目,向社会综合展
...[详细]
北纬网讯 近日,四川成雅工业园区管委会官方网站(http://www.cygyyq.com/)正式开通上线。网站开设了园区概况、园区动态、政务公开、园区建设、招商引资、企业风采等多个栏目,向社会综合展
...[详细]
-
China bans ICOs for being full of fraud and pyramid schemes
 The ICO -- Initial Coin Offering -- has recently become a very popular way to fund a startup, as it
...[详细]
The ICO -- Initial Coin Offering -- has recently become a very popular way to fund a startup, as it
...[详细]
-
South Korean lawmakers brace for US election as Harris, Trump diverge on North Korea
 Democratic presidential nominee and US Vice President Kamala Harris waves from the stage on Day 4 of
...[详细]
Democratic presidential nominee and US Vice President Kamala Harris waves from the stage on Day 4 of
...[详细]
-
College students can now get both Spotify and Hulu for just $5 a month
 College students that love binging TV shows and new music, rejoice: Spotify and Hulu are teaming up
...[详细]
College students that love binging TV shows and new music, rejoice: Spotify and Hulu are teaming up
...[详细]
-
 雅安日报讯工业和技改投资指标是衡量我市产业结构调整、工业经济活跃程度的重要参考。日前,我市列入2015年省重点工业及技改项目投资完成情况数据出炉,我市列入2015年省重点工业及技改项目计划11项(竣工
...[详细]
雅安日报讯工业和技改投资指标是衡量我市产业结构调整、工业经济活跃程度的重要参考。日前,我市列入2015年省重点工业及技改项目投资完成情况数据出炉,我市列入2015年省重点工业及技改项目计划11项(竣工
...[详细]
-
 福兴敬老院投入使用援建汇聚爱心温暖老人“房间舒适明亮,餐厅准备了可口的菜肴,活动室可以看书、下棋、跳舞……”谈起自己的新家——雨城区福兴敬老院,杨国兆等33位老人赞不绝口。雨城区福兴敬老院是上海市慈善
...[详细]
福兴敬老院投入使用援建汇聚爱心温暖老人“房间舒适明亮,餐厅准备了可口的菜肴,活动室可以看书、下棋、跳舞……”谈起自己的新家——雨城区福兴敬老院,杨国兆等33位老人赞不绝口。雨城区福兴敬老院是上海市慈善
...[详细]
-
'Hyundai Way': Auto giant's W121tr plan aims to seize mobility market lead
 Hyundai Motor Company President and CEO Chang Jae-hoon introduces the 10-year "Hyundai Way" strategy
...[详细]
Hyundai Motor Company President and CEO Chang Jae-hoon introduces the 10-year "Hyundai Way" strategy
...[详细]
-
Moon’s security adviser to hold 3
 President Moon Jae-in’s top security adviser is expected to arrive in Washington on Tuesday for thre
...[详细]
President Moon Jae-in’s top security adviser is expected to arrive in Washington on Tuesday for thre
...[详细]


- The Composer Has No Clothes
- S. Korea, US condemn NK missile launch in joint statement with several UNSC members
- Hands on with the LG V30's video recording
- Catholics in Korea increased nearly 50% over past 20 years: report
- How to trademark your TikTok phrase and protect your brand
- N. Korea unresponsive to regular contact via inter
- Snapchat's newest media partners: college newspapers